O Problema: "Funciona na minha máquina"
Imagine esta situação...

Alan: Desenvolvedor
"Meu aplicativo funciona perfeitamente no meu computador!"

Servidor de Produção
"ERRO: Dependências incompatíveis!"
"Mas funciona na minha máquina!"
- Todo desenvolvedor, em algum momento
Por que isso acontece?
Versões de Software
Python 3.8 vs Python 3.10
Bibliotecas
Versões diferentes de dependências
Configurações
Caminhos de arquivos, variáveis de ambiente
Sistema Operacional
Windows vs Linux vs macOS
A solução: Empacotar tudo junto!
Problema: Transporte de itens soltos

- Difícil de transportar
- Itens podem se perder
- Cada item precisa de tratamento diferente
Solução: Contêineres padronizados

- Formato padronizado
- Fácil de transportar
- Protege o conteúdo
- Mesmo tratamento para qualquer carga
Na programação, Docker resolve este problema criando "contêineres" para suas aplicações, garantindo que funcionem em qualquer lugar da mesma forma.
Vamos entender como isso funciona...
O que são Containers
Antes de entendermos o Docker, precisamos compreender o conceito fundamental de containers.
Um container é uma unidade padronizada de software que empacota o código e todas as suas dependências, permitindo que a aplicação seja executada de forma rápida e confiável de um ambiente computacional para outro.
Características dos Containers:
- Isolamento: Cada container opera de forma independente, sem interferir em outros containers ou no sistema hospedeiro
- Portabilidade: Executa o mesmo em qualquer ambiente, seja um notebook, servidor ou nuvem
- Eficiência: Compartilha o kernel do sistema operacional hospedeiro, tornando-os mais leves que máquinas virtuais
- Consistência: Garante que o software sempre execute da mesma maneira, independentemente do ambiente
Na tecnologia, containers solucionam o problema de "funciona na minha máquina", pois garantem que o ambiente de execução seja o mesmo em qualquer lugar. Um container inclui tudo que o aplicativo precisa para funcionar: código, runtime, bibliotecas, variáveis de ambiente, arquivos de configuração, etc.
O que é Docker
Docker é uma plataforma de código aberto que automatiza o processo de implantação de aplicativos dentro de contêineres. Isso permite que os aplicativos sejam executados no mesmo ambiente, independentemente de onde estejam sendo executados.
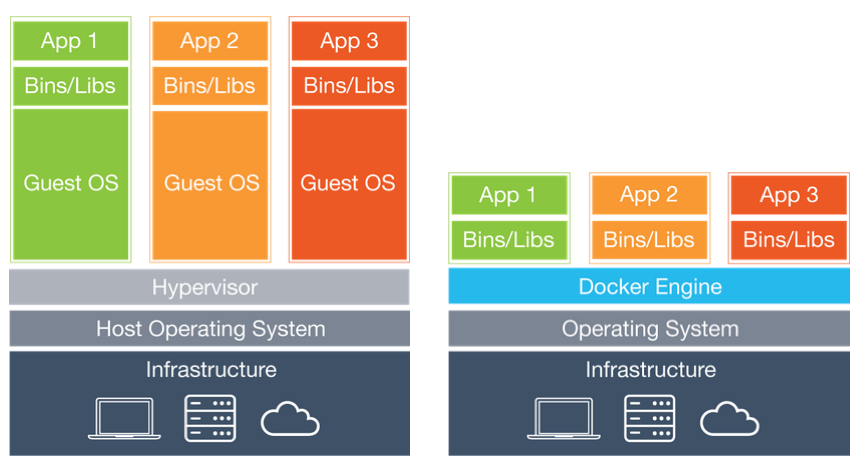
Docker (contêineres) vs Máquinas Virtuais
Um contêiner é uma unidade padronizada de software que empacota o código e todas as suas dependências para que o aplicativo seja executado de forma rápida e confiável de um ambiente computacional para outro.
Para que serve Docker
Docker serve para:
- Padronizar ambientes: "Funciona na minha máquina" deixa de ser um problema
- Isolar aplicações: Cada aplicação roda em seu próprio ambiente isolado
- Facilitar a implantação: Implantar aplicações se torna mais simples e previsível
- Escalar facilmente: Iniciar novos contêineres conforme a necessidade
- Gerenciar infraestrutura: Tratar a infraestrutura como código
Benefícios do uso de Docker
Consistência
Ambientes idênticos do desenvolvimento à produção
Velocidade
Implantação e inicialização muito mais rápidas que VMs
Isolamento
Aplicações isoladas sem interferir umas nas outras
Eficiência
Uso mais eficiente de recursos comparado às VMs
Portabilidade
Execute em qualquer lugar que tenha Docker instalado
Versionamento
Controle de versão das imagens e fácil rollback
Problemas que o Docker resolve
Problema: "Funciona na minha máquina"
Desenvolvedores e operações frequentemente enfrentam problemas quando o código funciona em um ambiente (como o laptop do desenvolvedor) mas falha em outro (como o servidor de produção).
Solução com Docker
Contêineres garantem que o ambiente de execução seja exatamente o mesmo em qualquer lugar.
Problema: Conflito de dependências
Aplicações diferentes podem precisar de versões diferentes da mesma biblioteca, causando conflitos.
Solução com Docker
Cada contêiner tem suas próprias dependências isoladas.
Problema: Configuração complexa de ambiente
Configurar ambientes de desenvolvimento pode ser demorado e propenso a erros.
Solução com Docker
Configuração automatizada através de Dockerfiles e Docker Compose.
Problema: Escalabilidade difícil
Escalar aplicações tradicionais pode ser um processo complexo.
Solução com Docker
Fácil escala horizontal com orquestradores como Docker Swarm e Kubernetes.
Instalando o Docker
Para aproveitar ao máximo este tutorial e executar os exemplos, você precisará ter o Docker instalado em seu computador. Siga o passo a passo abaixo conforme seu sistema operacional:
Instalação do Docker no Windows
Passo 1: Verificar requisitos do sistema
Antes de começar, certifique-se de que seu sistema atende aos requisitos mínimos:
- Windows 10 64-bit: Pro, Enterprise, ou Education (Build 16299 ou posterior)
- Ativar o recurso Hyper-V e Containers do Windows
- Virtualização habilitada na BIOS/UEFI
Se você estiver usando o Windows 10 Home, será necessário usar o Docker Toolbox ou atualizar para Windows 10 Pro.
Passo 2: Baixar o Docker Desktop
- Visite a página de download do Docker Desktop
- Clique no botão "Download for Windows"
- Aguarde o download do arquivo "Docker Desktop Installer.exe"
Passo 3: Instalar o Docker Desktop
- Localize o arquivo baixado e dê um duplo clique para iniciar a instalação
- Quando solicitado, verifique se as opções "Use WSL 2 instead of Hyper-V" e "Add shortcut to desktop" estão marcadas
- Clique em "Ok" para iniciar a instalação
- Aguarde a conclusão da instalação
Passo 4: Iniciar o Docker Desktop
- Após a instalação, o Docker Desktop pode iniciar automaticamente. Caso contrário, procure por "Docker Desktop" no menu Iniciar e clique nele
- Na primeira execução, pode levar alguns minutos para iniciar
- Quando solicitado, aceite os termos de serviço
- Você notará o ícone do Docker na área de notificação (bandeja do sistema) quando estiver em execução
Passo 5: Verificar a instalação
- Abra o Prompt de Comando ou PowerShell
- Digite o comando:
docker --versione pressione Enter - Você deverá ver a versão do Docker instalada, como:
Docker version 20.10.14, build a224086 - Para verificar se o Docker está funcionando corretamente, execute:
docker run hello-world
Possíveis problemas e soluções
- Erro de virtualização: Certifique-se de que a virtualização está habilitada na BIOS/UEFI do seu computador
- WSL 2 não instalado: Siga as instruções do instalador para instalar o WSL 2
- Conflitos de porta: Se outros serviços estiverem usando as portas necessárias, o Docker pode não iniciar corretamente
Instalação do Docker no macOS
Passo 1: Verificar requisitos do sistema
Antes de começar, certifique-se de que seu Mac atende aos requisitos mínimos:
- macOS 10.15 (Catalina) ou mais recente
- Para Macs com chip Apple Silicon (M1/M2): macOS 11 (Big Sur) ou mais recente
- Pelo menos 4 GB de RAM
Passo 2: Baixar o Docker Desktop
- Visite a página de download do Docker Desktop
- Clique no botão "Download for Mac"
- Selecione a versão apropriada para seu Mac:
- Para Macs com processador Intel: "Mac with Intel chip"
- Para Macs com chip Apple Silicon: "Mac with Apple chip"
- Aguarde o download do arquivo .dmg
Passo 3: Instalar o Docker Desktop
- Localize o arquivo .dmg baixado e dê um duplo clique para abri-lo
- Arraste o ícone do Docker para a pasta Applications, como indicado
- Acesse a pasta Applications e dê um duplo clique no ícone do Docker para iniciá-lo
- Quando solicitado, insira sua senha de administrador
- Leia e aceite os termos de serviço
Passo 4: Configurar o Docker Desktop
- Na primeira execução, o Docker solicitará permissões. Clique em "Ok" para permitir
- Aguarde o Docker iniciar (o ícone na barra de menu superior mostrará que está em execução)
- Você pode acessar as configurações clicando no ícone do Docker na barra de menu e selecionando "Preferences"
Passo 5: Verificar a instalação
- Abra o Terminal
- Digite o comando:
docker --versione pressione Enter - Você deverá ver a versão do Docker instalada
- Para verificar se o Docker está funcionando corretamente, execute:
docker run hello-world
Possíveis problemas e soluções
- Falha ao iniciar: Verifique as permissões de sistema no painel de Segurança e Privacidade das Preferências do Sistema
- Desempenho lento: Nas preferências do Docker, ajuste a quantidade de recursos (memória/CPU) alocados
- Para Apple Silicon: Alguns contêineres ainda não são nativos para ARM64, então você pode encontrar problemas de compatibilidade com imagens mais antigas
Instalação do Docker no Linux
Selecione sua distribuição Linux:
Passo 1: Atualizar o sistema
Certifique-se de que seu sistema está atualizado:
sudo apt update
sudo apt upgrade -yPasso 2: Instalar dependências necessárias
Instale os pacotes necessários para permitir o uso de repositórios HTTPS:
sudo apt install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-releasePasso 3: Adicionar a chave GPG oficial do Docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgPasso 4: Adicionar o repositório do Docker
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullPasso 5: Instalar o Docker Engine
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.ioPasso 6: Verificar a instalação
sudo docker run hello-worldSe tudo estiver correto, você verá uma mensagem de confirmação.
Passo 7: Configurar permissões (opcional, mas recomendado)
Para usar o Docker sem precisar do sudo, adicione seu usuário ao grupo docker:
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp dockerPasso 8: Configurar para iniciar com o sistema
sudo systemctl enable dockerPasso 1: Atualizar o sistema
Certifique-se de que seu sistema está atualizado:
sudo dnf update -yPasso 2: Adicionar o repositório Docker
sudo dnf config-manager --add-repo https://download.docker.com/linux/fedora/docker-ce.repoPasso 3: Instalar o Docker Engine
sudo dnf install -y docker-ce docker-ce-cli containerd.ioPasso 4: Iniciar o serviço Docker
sudo systemctl start dockerPasso 5: Verificar a instalação
sudo docker run hello-worldSe tudo estiver correto, você verá uma mensagem de confirmação.
Passo 6: Configurar permissões (opcional, mas recomendado)
Para usar o Docker sem precisar do sudo, adicione seu usuário ao grupo docker:
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp dockerPasso 7: Configurar para iniciar com o sistema
sudo systemctl enable dockerPasso 1: Atualizar o sistema
Certifique-se de que seu sistema está atualizado:
sudo apt update
sudo apt upgrade -yPasso 2: Instalar dependências necessárias
Instale os pacotes necessários para permitir o uso de repositórios HTTPS:
sudo apt install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-releasePasso 3: Adicionar a chave GPG oficial do Docker
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgPasso 4: Adicionar o repositório do Docker
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullPasso 5: Instalar o Docker Engine
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.ioPasso 6: Verificar a instalação
sudo docker run hello-worldSe tudo estiver correto, você verá uma mensagem de confirmação.
Passo 7: Configurar permissões (opcional, mas recomendado)
Para usar o Docker sem precisar do sudo, adicione seu usuário ao grupo docker:
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp dockerPasso 8: Configurar para iniciar com o sistema
sudo systemctl enable dockerPasso 1: Atualizar o sistema
Certifique-se de que seu sistema está atualizado:
sudo yum update -yPasso 2: Instalar utilitários necessários
sudo yum install -y yum-utilsPasso 3: Adicionar o repositório Docker
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repoPasso 4: Instalar o Docker Engine
sudo yum install -y docker-ce docker-ce-cli containerd.ioPasso 5: Iniciar o serviço Docker
sudo systemctl start dockerPasso 6: Verificar a instalação
sudo docker run hello-worldSe tudo estiver correto, você verá uma mensagem de confirmação.
Passo 7: Configurar permissões (opcional, mas recomendado)
Para usar o Docker sem precisar do sudo, adicione seu usuário ao grupo docker:
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp dockerPasso 8: Configurar para iniciar com o sistema
sudo systemctl enable dockerProblemas comuns na instalação do Docker no Linux
- Permissões negadas: Se você encontrar erros de permissão ao tentar executar comandos Docker, certifique-se de que adicionou seu usuário ao grupo docker e reiniciou a sessão
- Conflitos de porta: O Docker usa várias portas para seus serviços. Certifique-se de que essas portas não estejam sendo usadas por outros serviços
- Falha ao iniciar o daemon: Verifique os logs com
sudo journalctl -u docker.servicepara identificar o problema - Versões incompatíveis: Certifique-se de que todas as partes do Docker (Docker Engine, containerd, etc.) sejam de versões compatíveis
Exemplos práticos de uso do Docker
Exemplo 1: Dashboard de Dados com Streamlit
Criando um dashboard interativo de visualização de dados com Streamlit e empacotando-o em um contêiner Docker.
# app.py
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
# Configuração da página
st.set_page_config(page_title="Dashboard de Vendas", layout="wide")
# Título
st.title("Dashboard de Vendas - 2025")
# Carregar dados de exemplo
@st.cache_data
def load_data():
# NOTA: No exemplo isolado, usamos dados estáticos
# No exemplo do Docker Compose, estes dados virão da API
data = {
'Mês': ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun'],
'Vendas': [15000, 17500, 19800, 22300, 21500, 25000]
}
return pd.DataFrame(data)
df = load_data()
# Mostrar dados
st.subheader("Dados de Vendas")
st.dataframe(df)
# Visualização
st.subheader("Tendência de Vendas")
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(df['Mês'], df['Vendas'], marker='o')
ax.set_ylabel('Vendas (R$)')
ax.grid(True)
st.pyplot(fig)
# Métricas
st.subheader("Métricas")
col1, col2, col3 = st.columns(3)
with col1:
st.metric("Total de Vendas", f"R$ {df['Vendas'].sum():,.2f}")
with col2:
st.metric("Média Mensal", f"R$ {df['Vendas'].mean():,.2f}")
with col3:
st.metric("Crescimento", f"{((df['Vendas'].iloc[-1] / df['Vendas'].iloc[0]) - 1) * 100:.1f}%")# Dockerfile
FROM python:3.12-slim
WORKDIR /app
# Instalar dependências
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copiar código
COPY . .
# Expor porta para o Streamlit
EXPOSE 8501
# Comando para iniciar o Streamlit
CMD ["streamlit", "run", "app.py", "--server.address=0.0.0.0"]Criar arquivo de dependências
# Criar o arquivo requirements.txt
echo "streamlit==1.44.0
pandas==2.2.3
matplotlib==3.10.1" > requirements.txtConstruir a imagem Docker
# Construir a imagem Docker
docker build -t dashboard-vendas .Executar o contêiner
# Executar o contêiner
docker run -p 8501:8501 -d --name streamlit-app dashboard-vendas
# Acessar o dashboard
# Abra seu navegador em http://localhost:8501Benefícios neste exemplo:
- Dashboard de visualização de dados pronto para uso em qualquer ambiente
- Sem necessidade de instalar Python, Streamlit ou outras dependências no host
- Portabilidade para compartilhar facilmente com a equipe
- Ambiente isolado com versões específicas das bibliotecas
Exemplo 2: API de Dados com FastAPI
Criando uma API para acesso a dados usando FastAPI em um contêiner Docker.
# main.py
from fastapi import FastAPI, Query, Body
from pydantic import BaseModel
from typing import List, Optional
import os
from datetime import date
import pandas as pd
app = FastAPI(title="API de Dados de Vendas")
# Dados simulados - no exemplo isolado, usamos estes dados
# No exemplo do Docker Compose, estes dados viriam do banco PostgreSQL
vendas_df = pd.DataFrame({
'id': range(1, 11),
'produto': ['Laptop', 'Mouse', 'Teclado', 'Monitor', 'Headphone',
'Webcam', 'SSD', 'RAM', 'GPU', 'CPU'],
'categoria': ['Computadores', 'Acessórios', 'Acessórios', 'Periféricos', 'Áudio',
'Periféricos', 'Componentes', 'Componentes', 'Componentes', 'Componentes'],
'preco': [3500, 150, 200, 1200, 350, 180, 450, 300, 2000, 1500],
'quantidade_vendida': [12, 85, 63, 35, 42, 30, 55, 70, 22, 25]
})
class Produto(BaseModel):
id: int
produto: str
categoria: str
preco: float
quantidade_vendida: int
class ProdutoCreate(BaseModel):
produto: str
categoria: str
preco: float
quantidade_vendida: int
@app.get("/")
def read_root():
return {"mensagem": "API de Dados de Vendas"}
@app.get("/produtos", response_model=List[Produto])
def get_produtos(
categoria: Optional[str] = Query(None, description="Filtrar por categoria"),
min_preco: Optional[float] = Query(None, description="Preço mínimo"),
max_preco: Optional[float] = Query(None, description="Preço máximo")
):
df = vendas_df.copy()
if categoria:
df = df[df['categoria'] == categoria]
if min_preco is not None:
df = df[df['preco'] >= min_preco]
if max_preco is not None:
df = df[df['preco'] <= max_preco]
return df.to_dict(orient='records')
@app.get("/produtos/{produto_id}", response_model=Produto)
def get_produto(produto_id: int):
produto = vendas_df[vendas_df['id'] == produto_id]
if not produto.empty:
return produto.iloc[0].to_dict()
return {"erro": "Produto não encontrado"}
# Endpoint para inserir novos dados - disponível apenas no Docker Compose
@app.post("/produtos", response_model=Produto)
def criar_venda(venda: ProdutoCreate):
# No exemplo do Docker Compose, este método salvaria no PostgreSQL
global vendas_df
novo_id = vendas_df['id'].max() + 1 if not vendas_df.empty else 1
novo_produto = {
'id': novo_id,
**venda.dict()
}
vendas_df = pd.concat([vendas_df, pd.DataFrame([novo_produto])])
return novo_produto# Dockerfile
FROM python:3.12-slim
WORKDIR /app
# Copiar e instalar dependências
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copiar código
COPY . .
# Expor porta para a API
EXPOSE 8000
# Iniciar API com Uvicorn
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Criar arquivo de dependências
# Criar o arquivo requirements.txt
echo "fastapi==0.115.12
uvicorn==0.34.0
pandas==2.2.3
pydantic==2.11.1" > requirements.txtConstruir a imagem Docker
# Construir a imagem Docker
docker build -t api-vendas .Executar o contêiner
# Executar o contêiner
docker run -p 8000:8000 -d --name fastapi-app api-vendasTestar a API
# Testar a API
# Acesse http://localhost:8000/docs para ver a documentação interativaBenefícios neste exemplo:
- API de dados pronta para consumo por outras aplicações
- Documentação interativa automática com Swagger UI
- Isolamento de dependências e versões específicas
- Fácil implantação em qualquer ambiente que tenha Docker
Exemplo 3: Banco de Dados PostgreSQL
Executando um banco de dados PostgreSQL para análise de dados em um contêiner Docker.
Iniciar contêiner PostgreSQL
# Iniciar contêiner PostgreSQL
docker run --name postgres-dados -e POSTGRES_PASSWORD=segredo -e POSTGRES_USER=analista -e POSTGRES_DB=datawarehouse -p 5432:5432 -d postgres:14.8Verificar status do contêiner
# Verificar status do contêiner
docker psAcessar o banco de dados
# Executar o cliente psql dentro do contêiner
docker exec -it postgres-dados psql -U analista -d datawarehouse
# No exemplo isolado, o banco começa vazio
# No Docker Compose, será preenchido com dados iniciais e através da APIGerenciar o contêiner
# Parar o contêiner
docker stop postgres-dados
# Reiniciar o contêiner
docker start postgres-dados-- Criar tabela para armazenar dados
CREATE TABLE vendas (
id SERIAL PRIMARY KEY,
data_venda DATE NOT NULL,
produto VARCHAR(100) NOT NULL,
categoria VARCHAR(50) NOT NULL,
valor DECIMAL(10,2) NOT NULL,
quantidade INT NOT NULL
);
-- Inserir dados de exemplo
INSERT INTO vendas (data_venda, produto, categoria, valor, quantidade)
VALUES
('2025-01-15', 'Curso Python', 'Educação', 197.00, 45),
('2025-01-20', 'Assinatura BI', 'Software', 89.90, 28),
('2025-02-05', 'Consultoria', 'Serviços', 1200.00, 3),
('2025-02-12', 'Curso SQL', 'Educação', 147.00, 52),
('2025-03-01', 'Licença Tableau', 'Software', 999.00, 15);
-- Análise de vendas por categoria
SELECT
categoria,
COUNT(*) AS total_vendas,
SUM(valor * quantidade) AS receita_total,
AVG(valor) AS ticket_medio
FROM vendas
GROUP BY categoria
ORDER BY receita_total DESC;Executar PostgreSQL com volume
# Executar PostgreSQL com volume para persistência
docker run --name postgres-dados \
-e POSTGRES_PASSWORD=segredo \
-e POSTGRES_USER=analista \
-e POSTGRES_DB=datawarehouse \
-v postgres_data:/var/lib/postgresql/data \
-p 5432:5432 \
-d postgres:14.8Conexão externa
# Acessar usando ferramentas externas
# Host: localhost
# Port: 5432
# User: analista
# Password: segredo
# Database: datawarehouseBackup e restauração
# Criar backup do banco de dados
docker exec -t postgres-dados pg_dump -U analista -d datawarehouse > backup.sql
# Restaurar backup (para um contêiner novo)
# 1. Criar novo contêiner
docker run --name postgres-dados-novo -e POSTGRES_PASSWORD=segredo -e POSTGRES_USER=analista -e POSTGRES_DB=datawarehouse -v postgres_data_novo:/var/lib/postgresql/data -p 5433:5432 -d postgres:14.8
# 2. Restaurar dados
cat backup.sql | docker exec -i postgres-dados-novo psql -U analista -d datawarehouseBenefícios neste exemplo:
- Banco de dados para análise pronto para uso em segundos
- Persistência de dados com volumes Docker
- Isolamento completo do sistema host
- Fácil backup e restauração
- Possibilidade de executar múltiplas versões do PostgreSQL no mesmo sistema
Exemplo 4: Aplicação Completa de Análise de Dados com Docker Compose
Combinando PostgreSQL, FastAPI e Streamlit em uma stack completa de análise de dados usando Docker Compose.
# docker-compose.yml
services:
# Banco de dados
db:
image: postgres:14.8
container_name: postgres-analytics
environment:
- POSTGRES_USER=analista
- POSTGRES_PASSWORD=segredo
- POSTGRES_DB=datawarehouse
volumes:
- postgres_data:/var/lib/postgresql/data
# Inicialização do banco com script SQL
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
ports:
- "5432:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U analista -d datawarehouse"]
interval: 10s
timeout: 5s
retries: 5
# API para acesso aos dados
api:
build: ./api
container_name: dados-api
depends_on:
db:
condition: service_healthy
environment:
- DATABASE_URL=postgresql://analista:segredo@db:5432/datawarehouse
ports:
- "8000:8000"
# Dashboard para visualização
dashboard:
build: ./dashboard
container_name: dados-dashboard
depends_on:
- api
environment:
- API_URL=http://api:8000
ports:
- "8501:8501"
volumes:
postgres_data:# api/main.py
from fastapi import FastAPI, Depends, HTTPException, Body
from sqlalchemy import create_engine, Column, Integer, String, Float, Date, func
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, Session
import os
from datetime import date
from pydantic import BaseModel
from typing import List, Optional
# Configuração do banco de dados
DATABASE_URL = os.environ.get("DATABASE_URL")
engine = create_engine(DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
# Modelo SQLAlchemy
class VendaDB(Base):
__tablename__ = "vendas"
id = Column(Integer, primary_key=True, index=True)
data_venda = Column(Date)
produto = Column(String)
categoria = Column(String)
valor = Column(Float)
quantidade = Column(Integer)
# Modelo Pydantic para leitura
class Venda(BaseModel):
id: int
data_venda: date
produto: str
categoria: str
valor: float
quantidade: int
class Config:
orm_mode = True
# Modelo Pydantic para criação
class VendaCreate(BaseModel):
data_venda: date
produto: str
categoria: str
valor: float
quantidade: int
# Dependência para obter a sessão do banco
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
app = FastAPI(title="API de Análise de Dados")
@app.get("/vendas", response_model=List[Venda])
def listar_vendas(db: Session = Depends(get_db)):
return db.query(VendaDB).all()
@app.get("/vendas/categoria/{categoria}", response_model=List[Venda])
def vendas_por_categoria(categoria: str, db: Session = Depends(get_db)):
return db.query(VendaDB).filter(VendaDB.categoria == categoria).all()
@app.get("/vendas/analise")
def analise_vendas(db: Session = Depends(get_db)):
resultado = db.query(
VendaDB.categoria,
func.count(VendaDB.id).label("total_vendas"),
func.sum(VendaDB.valor * VendaDB.quantidade).label("receita_total"),
func.avg(VendaDB.valor).label("ticket_medio")
).group_by(VendaDB.categoria).all()
return [
{
"categoria": r.categoria,
"total_vendas": r.total_vendas,
"receita_total": float(r.receita_total),
"ticket_medio": float(r.ticket_medio)
}
for r in resultado
]
# Endpoint para inserir novos dados - disponível apenas no Docker Compose
@app.post("/vendas", response_model=Venda)
def criar_venda(venda: VendaCreate, db: Session = Depends(get_db)):
nova_venda = VendaDB(**venda.dict())
db.add(nova_venda)
db.commit()
db.refresh(nova_venda)
return nova_venda# dashboard/app.py
import streamlit as st
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import requests
import os
import json
from datetime import datetime
# Configuração
API_URL = os.environ.get("API_URL", "http://api:8000")
st.set_page_config(
page_title="Dashboard de Análise de Vendas",
layout="wide",
initial_sidebar_state="expanded"
)
# Título
st.title("Dashboard de Análise de Vendas")
st.write("Dashboard interativo para análise de dados de vendas")
# Funções para carregar dados da API
@st.cache_data(ttl=300)
def carregar_vendas():
response = requests.get(f"{API_URL}/vendas")
return pd.DataFrame(response.json())
@st.cache_data(ttl=300)
def carregar_analise():
response = requests.get(f"{API_URL}/vendas/analise")
return pd.DataFrame(response.json())
# Função para inserir novos dados
def inserir_venda(dados):
response = requests.post(f"{API_URL}/vendas", json=dados)
return response.status_code == 200 or response.status_code == 201
try:
# Carregar dados
df_vendas = carregar_vendas()
df_analise = carregar_analise()
# Criar abas para separar visualização e entrada de dados
tab1, tab2 = st.tabs(["Visualização de Dados", "Inserir Novos Dados"])
with tab1:
# Layout em colunas
col1, col2 = st.columns(2)
# Coluna 1: Gráfico de barras - Receita por categoria
with col1:
st.subheader("Receita Total por Categoria")
fig1 = px.bar(
df_analise,
x="categoria",
y="receita_total",
text_auto=True,
color="categoria",
title="Receita Total por Categoria de Produto"
)
st.plotly_chart(fig1, use_container_width=True)
# Coluna 2: Gráfico de pizza - Proporção de vendas
with col2:
st.subheader("Proporção de Vendas por Categoria")
fig2 = px.pie(
df_analise,
values="total_vendas",
names="categoria",
title="Distribuição de Vendas por Categoria"
)
st.plotly_chart(fig2, use_container_width=True)
# Tabela completa
st.subheader("Dados de Vendas")
st.dataframe(df_vendas)
# Filtro por categoria
st.sidebar.title("Filtros")
categorias = ["Todas"] + sorted(df_vendas["categoria"].unique().tolist())
categoria_selecionada = st.sidebar.selectbox("Selecione uma categoria:", categorias)
if categoria_selecionada != "Todas":
df_filtrado = df_vendas[df_vendas["categoria"] == categoria_selecionada]
st.subheader(f"Vendas na categoria: {categoria_selecionada}")
st.dataframe(df_filtrado)
# Gráfico de linha para a categoria
if not df_filtrado.empty:
df_por_data = df_filtrado.groupby("data_venda").agg(
{"valor": lambda x: (x * df_filtrado["quantidade"]).sum()}
).reset_index()
df_por_data.columns = ["data", "receita"]
fig3 = px.line(
df_por_data,
x="data",
y="receita",
markers=True,
title=f"Evolução de Receita: {categoria_selecionada}"
)
st.plotly_chart(fig3, use_container_width=True)
with tab2:
# Formulário para adicionar novas vendas
st.subheader("Adicionar Nova Venda")
with st.form("nova_venda_form"):
data_venda = st.date_input("Data da Venda", datetime.now().date())
produto = st.text_input("Nome do Produto")
# Usar categorias existentes ou permitir nova
usar_categoria_existente = st.checkbox("Usar categoria existente", value=True)
if usar_categoria_existente and not df_vendas.empty:
categoria = st.selectbox("Categoria", sorted(df_vendas["categoria"].unique().tolist()))
else:
categoria = st.text_input("Nova Categoria")
valor = st.number_input("Valor Unitário (R$)", min_value=0.01, format="%.2f")
quantidade = st.number_input("Quantidade", min_value=1, step=1)
submitted = st.form_submit_button("Adicionar Venda")
if submitted:
if not produto or not categoria:
st.error("Todos os campos são obrigatórios!")
else:
nova_venda = {
"data_venda": data_venda.isoformat(),
"produto": produto,
"categoria": categoria,
"valor": valor,
"quantidade": quantidade
}
if inserir_venda(nova_venda):
st.success("Venda adicionada com sucesso!")
st.cache_data.clear() # Limpar cache para recarregar dados
else:
st.error("Erro ao adicionar venda. Verifique os dados e tente novamente.")
except Exception as e:
st.error(f"Erro ao carregar dados: {e}")
st.warning("Verifique se a API está disponível e funcionando corretamente.")Estrutura inicial do projeto
# Estrutura de diretórios
mkdir -p projeto-dados/{api,dashboard}Script de inicialização do banco
# Criar script de inicialização do banco
cat > init.sql << 'EOF'
CREATE TABLE vendas (
id SERIAL PRIMARY KEY,
data_venda DATE NOT NULL,
produto VARCHAR(100) NOT NULL,
categoria VARCHAR(50) NOT NULL,
valor DECIMAL(10,2) NOT NULL,
quantidade INT NOT NULL
);
INSERT INTO vendas (data_venda, produto, categoria, valor, quantidade)
VALUES
('2025-01-15', 'Curso Python', 'Educação', 197.00, 45),
('2025-01-20', 'Assinatura BI', 'Software', 89.90, 28),
('2025-02-05', 'Consultoria', 'Serviços', 1200.00, 3),
('2025-02-12', 'Curso SQL', 'Educação', 147.00, 52),
('2025-03-01', 'Licença Tableau', 'Software', 999.00, 15);
EOFConfiguração da API
# Criar Dockerfile para a API
cat > api/Dockerfile << 'EOF'
FROM python:3.12-slim
WORKDIR /app
# Copiar e instalar dependências
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copiar código
COPY . .
# Expor porta para a API
EXPOSE 8000
# Iniciar API com Uvicorn
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
EOF
# Requisitos para a API
cat > api/requirements.txt << 'EOF'
fastapi==0.115.12
uvicorn==0.34.0
pydantic==2.11.1
sqlalchemy==2.0.22
psycopg2-binary==2.9.9
EOFConfiguração do Dashboard
# Criar Dockerfile para o Dashboard
cat > dashboard/Dockerfile << 'EOF'
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["streamlit", "run", "app.py", "--server.address=0.0.0.0"]
EOF
# Requisitos para o Dashboard
cat > dashboard/requirements.txt << 'EOF'
streamlit==1.44.0
pandas==2.2.3
plotly==5.18.0
requests==2.31.0
EOFGerenciar Docker Compose
# Iniciar todos os serviços
docker-compose up -d
# Verificar logs dos serviços
docker-compose logs -f
# Parar todos os serviços
docker-compose down
# Parar e remover volumes (limpar dados)
docker-compose down -vBenefícios neste exemplo:
- Stack completa de análise de dados orquestrada com um único comando
- Comunicação entre serviços usando a rede interna do Docker
- Fluxo de dados bidirecional: inserção de dados via dashboard → API → banco de dados
- Atualização em tempo real dos gráficos após inserção de novos dados
- Persistência de dados com volumes Docker
- Pipeline de dados completo com feedback circular
Fluxo completo de dados:
- Usuário insere dados no dashboard Streamlit
- Dashboard envia dados para a API FastAPI
- API persiste dados no PostgreSQL
- Dashboard consulta API para atualizar visualizações
- API obtém dados do PostgreSQL